K-Means算法是最古老也是應用最廣泛的聚類算法,它使用質心定義原型,質心是一組點的均值,通常該算法用于n維連續空間中的對象。
K-Means算法流程
step1:選擇K個點作為初始質心
step2:repeat
將每個點指派到最近的質心,形成K個簇
重新計算每個簇的質心
until 質心不在變化
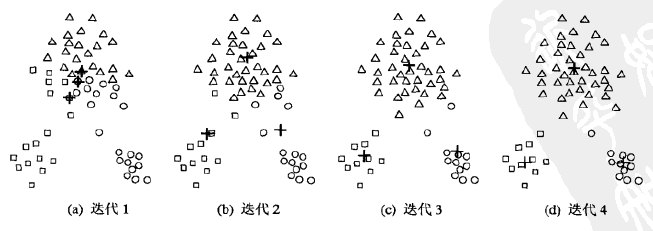
例如下圖的樣本集,初始選擇是三個質心比較集中,但是迭代3次之后,質心趨于穩定,并將樣本集分為3部分
我們對每一個步驟都進行分析
step1:選擇K個點作為初始質心
這一步首先要知道K的值,也就是說K是手動設置的,而不是像EM算法那樣自動聚類成n個簇
其次,如何選擇初始質心
最簡單的方式無異于,隨機選取質心了,然后多次運行,取效果最好的那個結果。這個方法,簡單但不見得有效,有很大的可能是得到局部最優。
另一種復雜的方式是,隨機選取一個質心,然后計算離這個質心最遠的樣本點,對于每個后繼質心都選取已經選取過的質心的最遠點。使用這種方式,可以確保質心是隨機的,并且是散開的。
step2:repeat
將每個點指派到最近的質心,形成K個簇
重新計算每個簇的質心
until 質心不在變化
如何定義最近的概念,對于歐式空間中的點,可以使用歐式空間,對于文檔可以用余弦相似性等等。對于給定的數據,可能適應與多種合適的鄰近性度量。